
The Agentic Future (06.23.26): AI Inference Wars
Every prompt now has a cost; as trillions of agents deploy live products, inference is turning into a lucrative market: routed, priced & fought over by cloud giants, GPU networks & crypto AI protocols


This Crypto AI & Robotics newsletter consists of three key parts:
Snippet Partner: NuNet
Theme of the Week: AI Inference Wars
Landscape Analysis: OpenRouter, Nunet, Darkbloom (Eigen Labs), Venice, Dolphin, Openserv, Ionet, Akash, Chutes, Targon, C0mpute (ft: Virtuals)
If you have any questions feel free to reach out to me on X or message my business X account ‘Khala Research’



NuNet is highly relevant to this week’s theme. As inference moves beyond centralised cloud providers, orchestration across distributed compute becomes a much bigger part of the market.
That is where NuNet fits in.
Rather than simply being another GPU marketplace, NuNet is focused on coordinating workloads across different machines, devices and infrastructure environments:
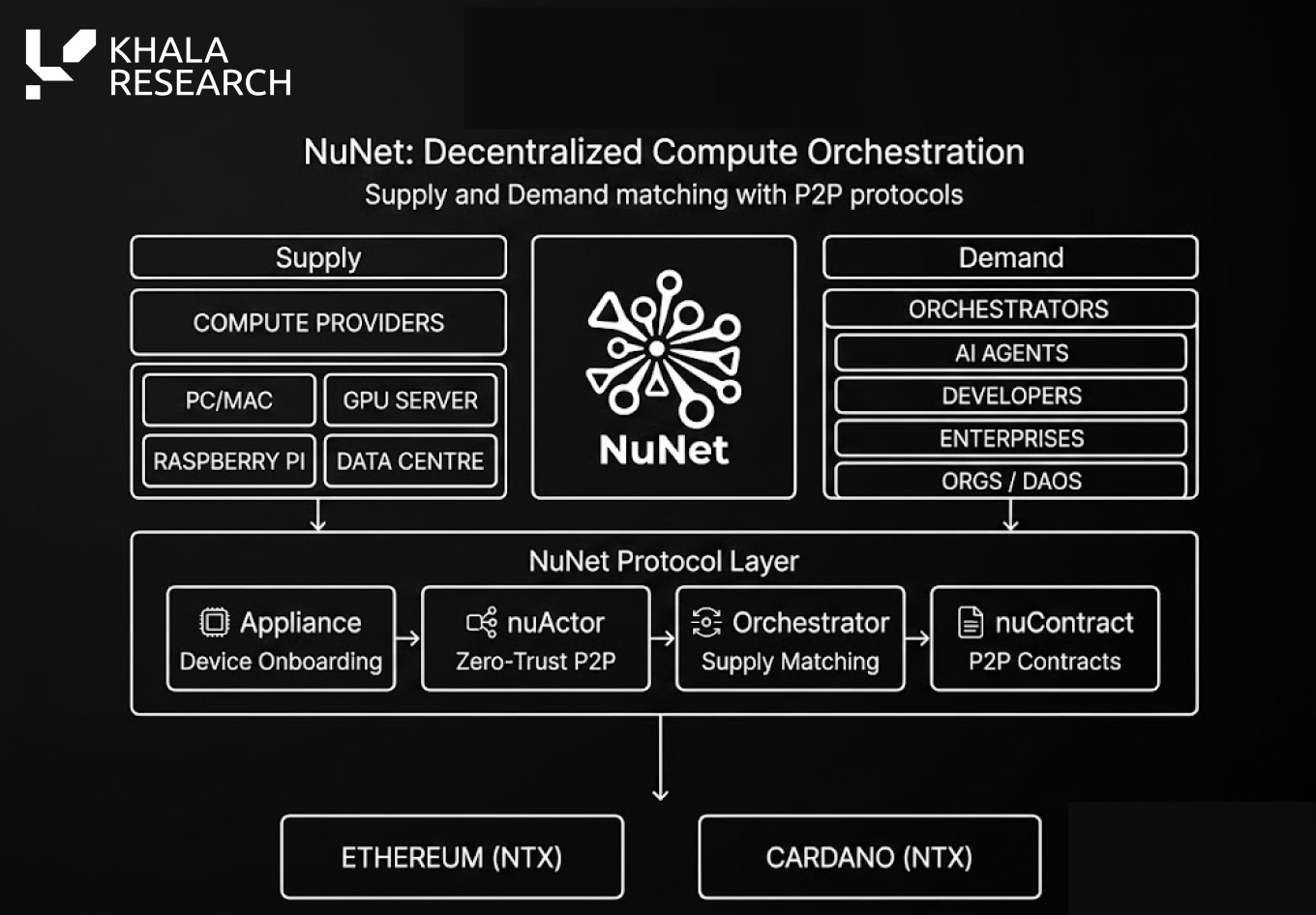
We cover why that matters in more detail later in the article
This newsletter goes out weekly to 7.2k+ subscribers.
Please don’t hesitate to message me directly for sponsorship or partnership enquiries.

“AI Inference Wars”
The last AI cycle was about training, but the next one is increasingly about inference.
Many of you may be hearing the word “inference” for the first time… So what is it?
Training creates the model. Inference is when someone asks that model a question or gives it a task, and the model produces an answer.
1. AI Inference Market Overview
Training gets the headlines because it’s the brain behind the outputs that so many of us have been blown away by.
Currently, inference receives a large portion of the economic benefits because every prompt, agent loop, image, trade, tool call and code edit has to run somewhere.
That economic activity is showing no signs of slowing down; openrouter saw 47 trillion tokens flow through its protocol last week alone:



So what makes up an inference market? Well, it needs a few things:
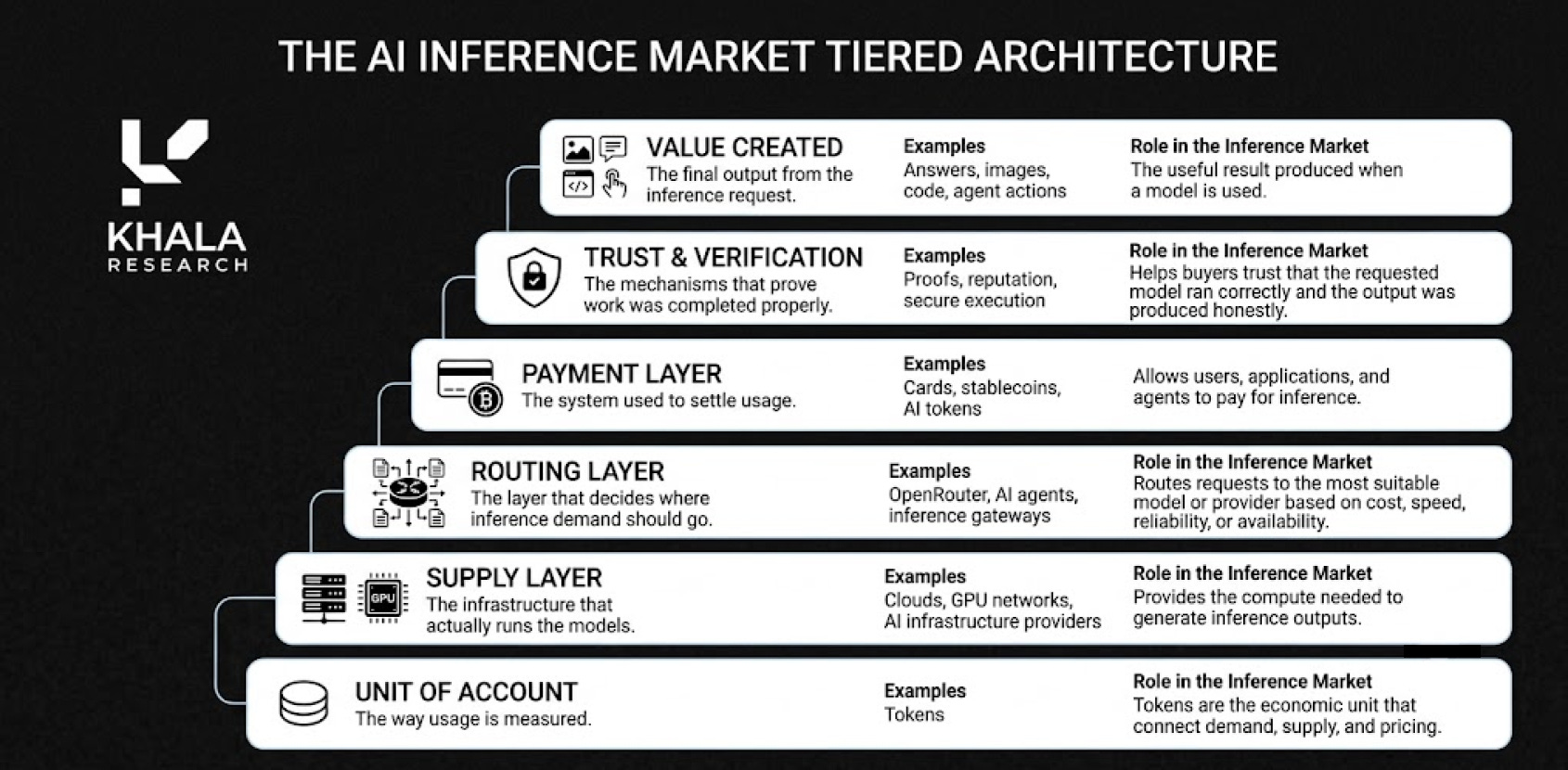
Tokens are becoming the unit of account.
OpenRouter is fast becoming THE exchange layer; 47 trillion tokens were used through the LLM marketplace last week alone
Fireworks, Together, Replicate, Baseten, Groq and the hyperscalers are becoming the professional supply side
Chutes, Akash, io.net, Nosana, Targon, Venice, NuNet and other crypto AI networks are trying to build the permissionless version underneath
The mistake is to compare all of these providers as if they are competing in the same market; they are not.
Traditional providers sell reliability, developer experience and enterprise procurement
Crypto AI networks sell cheaper supply, open access, privacy, verifiability and new incentive loops
More recently opened many peoples’ eyes to the risks of becoming reliant on single frontier proprietary model for tokens as Anthropic banned use of its mythos model (Fable 5) for anyone outside of the USA:


The interesting part is where the two worlds start to overlap; a focus on privacy, confidential compute or agent-native payments (Venice & Targon feature well here).
3. How to view the AI Compute market
The better way to view the market is:
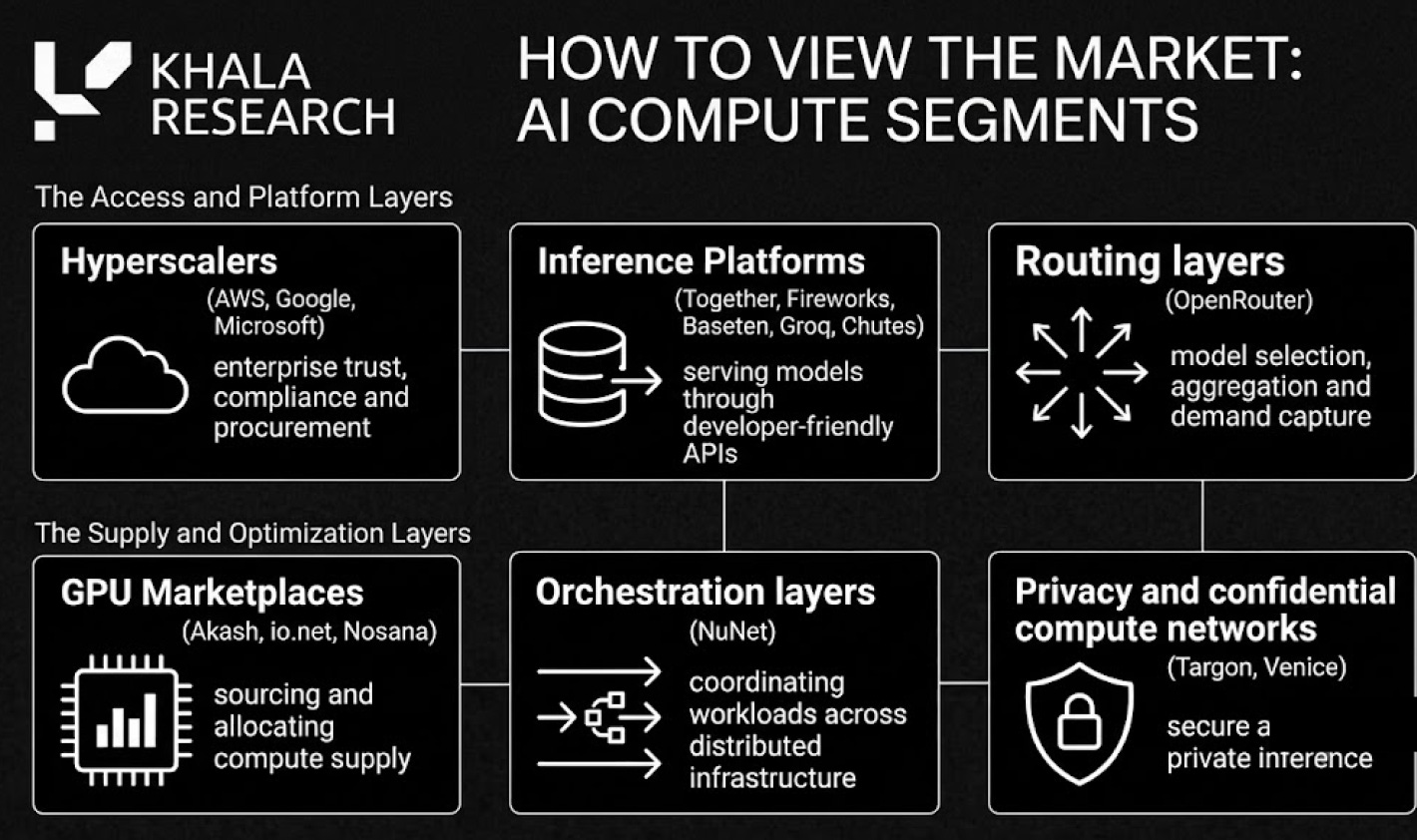
The interesting part is not where these worlds differ, but where they start to overlap; traditional providers sell reliability, developer experience and enterprise procurement.
Traditional providers generally compete on reliability, support and developer experience, while Crypto AI networks generally compete on open access, lower-cost supply, privacy, verifiability and novel incentive mechanisms to co-ordinate capital seamlessly around the globe
4. Why Inference Is The Real AI Market
The model layer still matters, but model quality is compressing faster than most people expected. Open source models are performing at 90-95% the quality of frontier models, but at 10% of the cost (e.g. GLM-5.2 from Zai):


Open models keep improving. Chinese labs keep pushing down pricing. Frontier models still command a premium, but below that top tier, token pricing is becoming competitive very quickly.



This is why the routing layer matters; If the same open model can be served by five different providers at five different prices, developers do not want to hardcode one endpoint forever so they want a router.
A router can choose by:
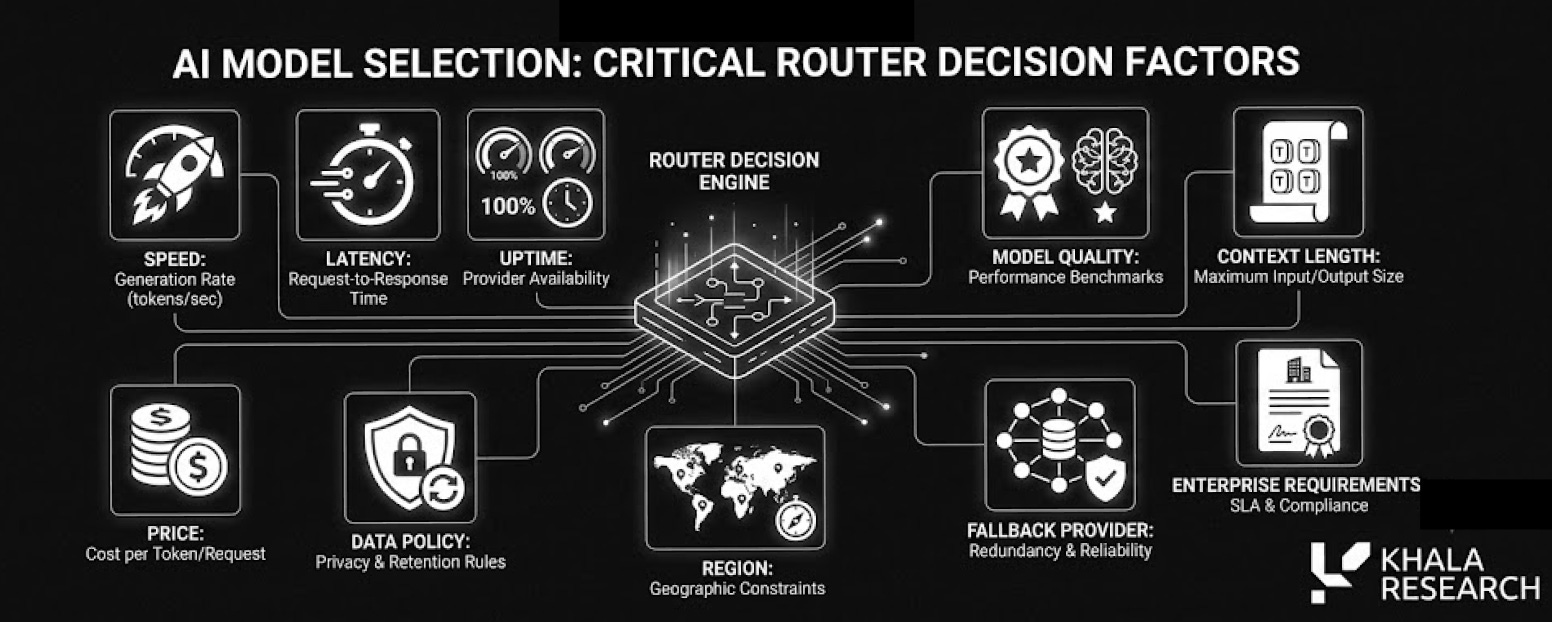
The router sits above the providers and turns a messy landscape into one clean interface:
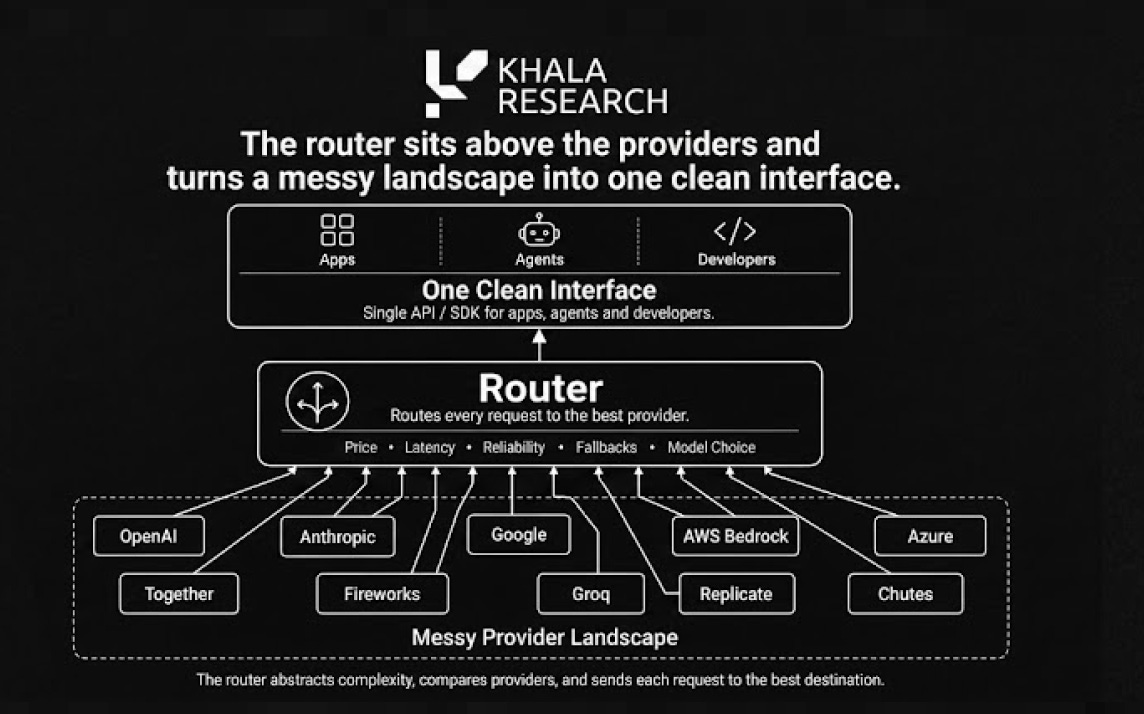
This is what OpenRouter got right, and why Funds splashed $113m in a recent Series B, to plug a clear gap in the market:


OpenRouter is fast becoming the market interface; one key can access hundreds of models across many providers. The real value is not the model list. The real value is that the same request can be routed to the best provider for that job.
This starts to look like an energy market; the user does not care which power plant made the electricity. They care that the lights turn on, the price is fair and the system does not break.
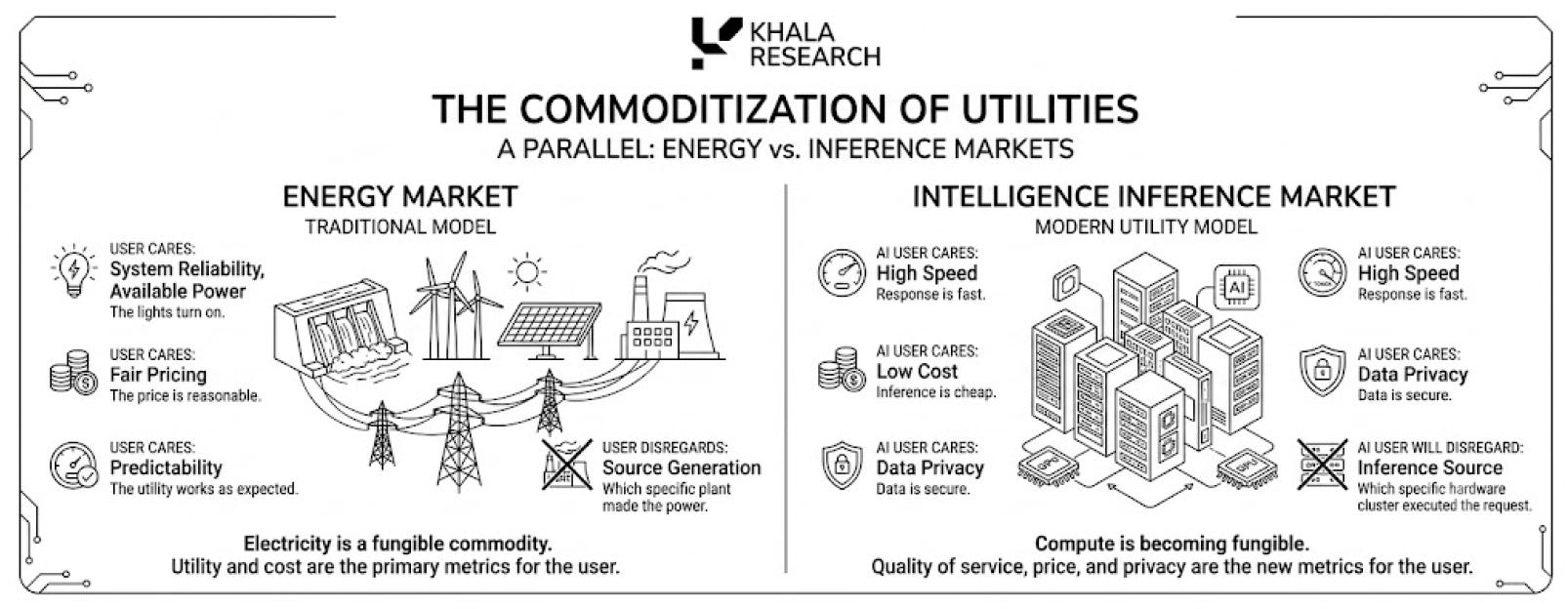
AI users will increasingly think the same way, they won’t care which GPU cluster served the token. They will only care that the response is fast, cheap, private and reliable.
5. Traditional Inference Providers

The traditional side is splitting into four groups.
i) Hyperscalers: AWS, Google and Microsoft
They win on enterprise trust. Large companies are not just buying tokens; they are buying compliance, security, procurement comfort and someone accountable when things break.
ii) Routing markets: OpenRouter and AI gateways
Routers sit above model providers and send each request to the best option. As model leadership changes week to week, hardcoding one model looks increasingly weak. AI needs aggregators, just like crypto does.
iii) Optimised open-model serving: Together, Fireworks, Baseten and Groq
These are not just cheap APIs. They are performance infrastructure companies, focused on speed, batching, scaling, fine-tuning, custom endpoints and production support.
iv) Model marketplaces: Replicate and Hugging Face-style platforms
Inference is broader than chat. Image, video, speech, embeddings, robotics models, simulations and multimodal agents all need models to run. Marketplaces make that long-tail model demand easy to access.
6. Crypto AI Inference Providers
The crypto side gets flattened into one phrase: decentralised compute, which is too vague; there are at least five different categories:
serverless inference networks
decentralised GPU marketplaces
confidential compute networks
private AI apps and gateways
orchestration layers
They should not be analysed the same way.
i) Chutes: Crypto-Native Inference
Chutes is best understood as a decentralised inference platform, not just a GPU marketplace.
The point is simple: developers do not want to rent GPUs or manage infrastructure. They want an endpoint that works. Chutes focuses on serving open-source models through a familiar API, while using decentralised GPU supply underneath.
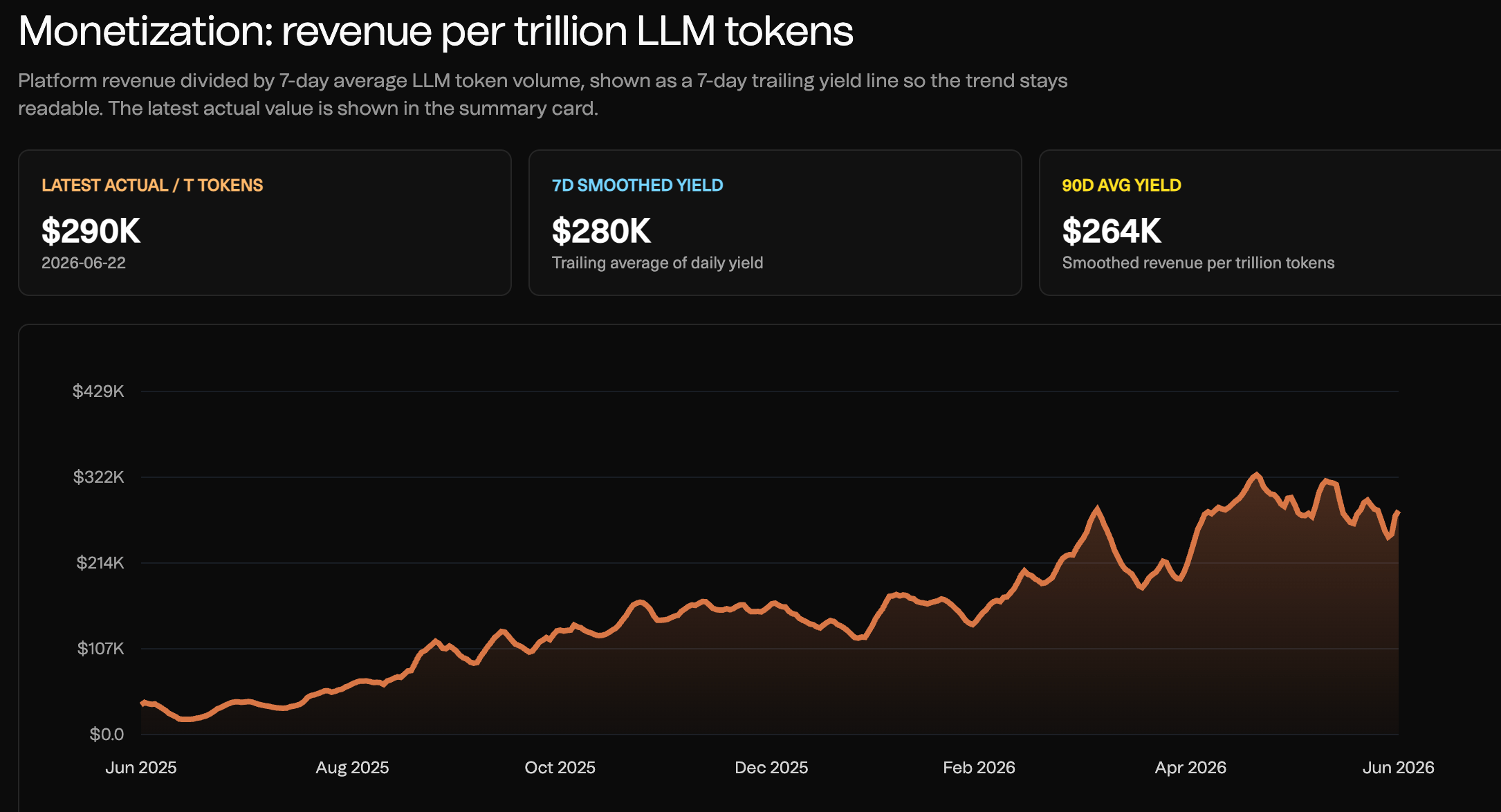
The key question is whether it can turn headline usage into paid, recurring demand. Cheap tokens are useful, but only if developers trust the uptime, latency and reliability.
Its revenue per trillion tokens continues to trend up, showing potential for sustained profitability/viability:
ii) Akash: The GPU Auction Layer
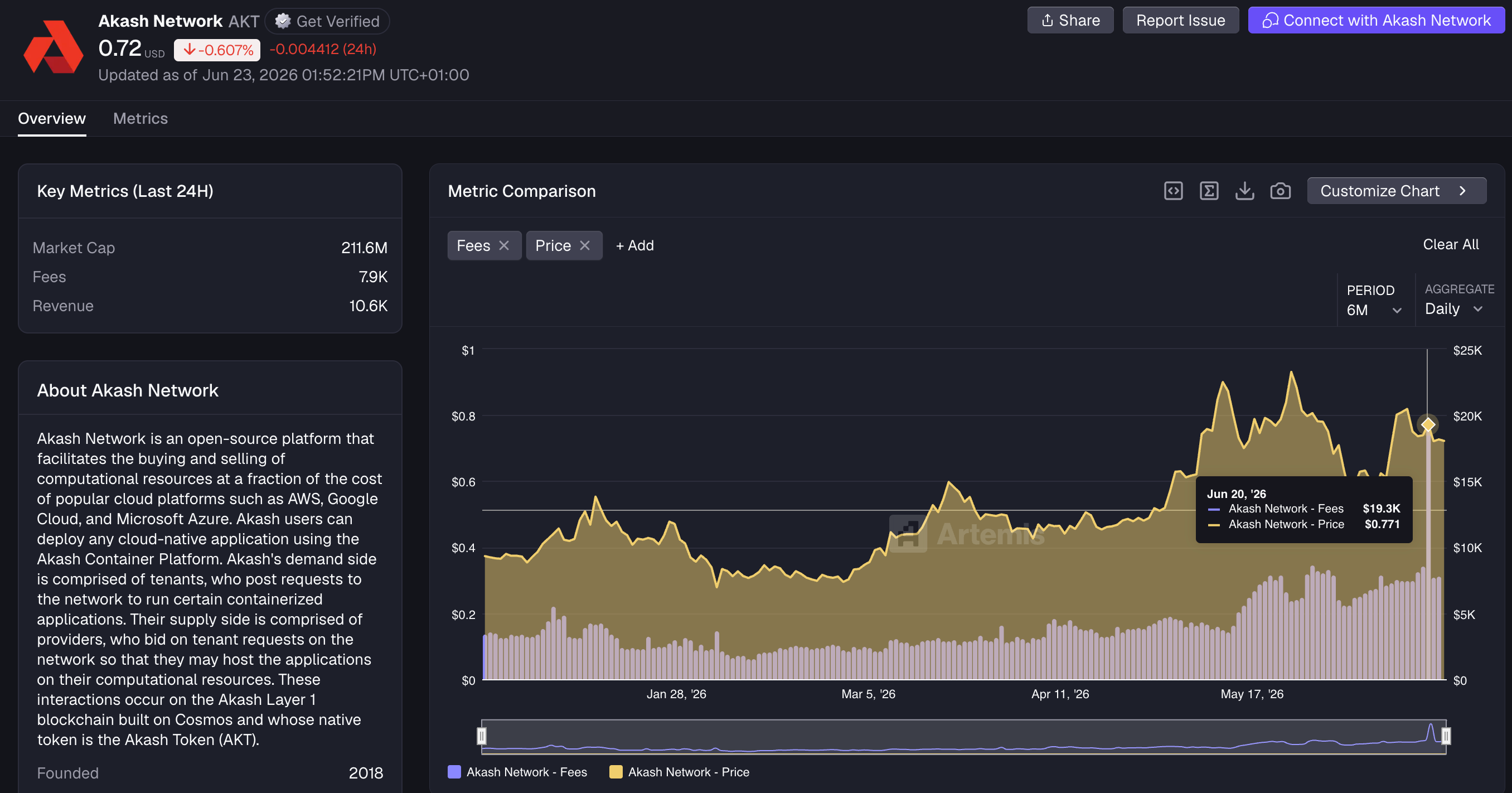
Akash is a decentralised cloud marketplace.
Users define the compute they need, providers compete to supply it, and workloads run through leases. This makes Akash more of a compute marketplace than a direct inference router.
Its strongest fit is price-sensitive workloads that can tolerate more infrastructure variability and do not need deep integration with AWS, Azure or Google Cloud.
Fees and token price are somewhat correlated and are on the rise:
iii) io.net: Decentralised GPU Clouds
io.net is closer to decentralised GPU cloud providers.
Its core pitch is access to distributed GPU supply at lower cost and with faster provisioning than traditional cloud routes. That is useful for AI teams that need compute but do not want long cloud contracts or hyperscaler pricing.
The challenge is execution: hardware verification, reliability, scheduling, support and consistent performance. Raw GPU access is valuable, but the higher-margin layer is still routing, managed inference and orchestration
Ionet has been one of the leading performers over the past 30 days with $12.3m annualized revenue:


iv) Targon: Confidential Compute
Targon is focused on confidential compute for AI workloads.
The problem it addresses is obvious: many users will not run sensitive prompts, models or data on infrastructure operated by unknown third parties.
Targon’s answer is protected execution through trusted execution environments, encrypted virtual machines, remote attestation and confidential GPU infrastructure. In plain English, the aim is to prove the workload is running in a secure environment and reduce what operators can see.
This is relevant for private inference, especially in areas like finance, healthcare and enterprise AI. The caveat is that confidential compute is not magic. It shifts trust toward hardware, firmware and attestation systems.
Last year the protocol reported annual revenue of $10.4m and co-authored a research paper with Intel on “Decentralized compute on untrusted hardware”

v) Darkbloom: Private Inference on Idle Macs
Darkbloom takes a different route.
Instead of sharding a large model across random GPUs, it turns idle Apple Silicon Macs into a private inference network. The Mac runs the model locally, while requests are encrypted and routed to verified providers.
The wedge is privacy and cost, not maximum frontier-model performance.
This is useful because “no node holds the full model” does not automatically mean prompts are private. Darkbloom is more explicit about the privacy problem, but still needs to prove supply scale, performance and developer trust.
It’s now up to 300 Machines on the network with 2 billion tokens served across 1 million requests:



vi) Venice: Private Inference For Consumers
Venice occupies a different position in the market from networks such as Akash or io.net. Rather than functioning primarily as a GPU marketplace, it is better viewed as a private AI application and inference gateway.
Throughput of said gateway is now up to 85 billion tokens daily:


Most users want an AI product that respects their privacy and gives them access to capable models without extensive data collection.
Venice packages the infrastructure thesis into a consumer-facing experience built around private prompts, open-source models, uncensored access, API functionality and tokenised compute through VVV and DIEM.
The DIEM component is particularly interesting because it points toward a broader idea about agent economies; providing access to $1 of compute per day (into perpetuity?). That’s something the market has attached a decent price tag to recently:

If agents require continuous access to inference, then compute credits begin to resemble an agent-native asset that entire secondary markets can be built around:


An agent that can directly hold and spend compute rights is arguably more practical than one that depends on a human periodically funding a credit card.
This highlights a deeper crypto AI thesis.
Agents will ultimately need access to money, identity, memory and compute, and crypto systems provide a framework for making those resources programmable.
Venice is therefore NOT competing directly with OpenRouter on model breadth. Instead, it is competing on privacy, access and tokenised compute.
That is a legitimate niche, although the key question remains whether demand for private AI products becomes large enough to sustain the token model beyond the current narrative cycle; my bet is privacy is only going to become a stronger narrative as AI proliferates.
vii) NuNet: Orchestration Across Distributed Compute
NuNet is often grouped with decentralised compute projects, but the more useful framing is “orchestration”.
Orchestration involves matching workloads to the most appropriate compute resources and coordinating execution across different machines, environments and locations.
This becomes increasingly important as AI expands beyond centralised cloud infrastructure.
Future AI systems are likely to operate across cloud GPUs, edge devices, local servers, robots, phones, sensors and decentralised provider networks.
As that shift occurs, not every decision can depend on a distant cloud endpoint:
A warehouse robot may not be able to wait for a cross-region API response.
A drone cannot assume perfect connectivity at all times.
A field robot operating in remote conditions may need to perform inference locally whenever network access becomes unreliable.
For that reason, orchestration is emerging as a meaningful category in its own right.
The challenge for NuNet is whether it can transform this coordination problem into a functioning economic network with sufficient supply, demand and developer adoption.
viii) OpenServ: Agent Orchestration, Not Pure Inference
OpenServ is not best understood as a decentralised inference network; it’s better framed as an agent infrastructure and orchestration platform.
That matters because agents are one of the clearest future sources of inference demand. A normal chatbot might call a model once. An agent calls models repeatedly. It reasons, uses tools, checks outputs, calls another model, takes an action and then loops again.
That creates heavy, recurring inference demand that is getting noticed within our little crypto bubble:

OpenServ is therefore relevant to the inference market from the demand side rather than the supply side. If the platform can become a useful place for developers to build, deploy and coordinate agents, then it naturally becomes a layer that can route inference to different providers underneath.
The key question is whether OpenServ becomes a real agent execution layer or simply another agent marketplace with a token attached.
I’d hazard a guess that the capabilities behind this team extend beyond the latter, with several notable benhcmark performances for its reasoning framework and its own proprietary models on its roadmap:

If OpenServ can own the agentic operational workflow, inference becomes an input into the platform rather than the main product itself.
In an agentic world, the most valuable layer will become the place where agents spend a lot of their ongoing time and resources.
ix) Dolphin AI: Product-Led Decentralised Inference
Dolphin AI is interesting for a different reason; it started from model demand rather than a GPU marketplace.
The Dolphin model family already had a reputation for uncensored open models, and that gives the network a clearer reason to exist:



This is important because many decentralised inference projects begin with supply first: “we have GPUs, now who wants to buy them?”
Dolphin is closer to the opposite; It begins with a set of models people already want to use, then builds a decentralised inference network around that demand.
Its architecture is often described as peer-to-pool, which means:
GPU owners contribute capacity into model-specific pools, rather than each buyer renting a specific node directly.
Requests are routed into the pool, and;
available nodes process them.
That is a better design for unreliable consumer supply.
If someone is contributing an idle gaming GPU, they may not keep it online forever. A pool-based model can absorb that more naturally than a one-to-one rental marketplace.
The more interesting part is verification.
Dolphin has been pushing live-weight proofs. In simple terms, this means checking that the model weights actually loaded in the serving process match the model the node claims to be running.
That matters because cheating is one of the hardest problems in decentralised inference.
A node could claim to run an expensive model while secretly serving a smaller, cheaper or more quantised version.
If the network cannot detect that, the whole market loses credibility.
x) c0mpute: Distributed Inference For Agents
c0mpute is worth watching because it is trying to solve one of the hardest problems in decentralised inference: running large models across scattered GPUs on the open internet. This video explainer of the problem it’s solving is fantastic:

Its Shard engine splits a model across multiple machines, rather than requiring one huge server to hold the full model. That makes it relevant for frontier-scale open models that may be too large or too restricted for normal hosting routes.
The Virtuals link is the key demand-side angle. Virtuals is building an agent economy, and agents are heavy inference users. They plan, call tools, transact, check results and loop. That creates recurring demand for cheap, open and censorship-resistant inference:


The caveat is that this is still early. c0mpute needs to prove performance under real load, node reliability, verification and prompt privacy.
But the direction is important: GPU marketplaces sell access to compute; c0mpute is trying to distribute the model itself
7. Traditional vs Crypto Inference

8. What To Watch
i) Paid token volume
The market should place less emphasis on raw token-processing statistics unless those tokens generate revenue. Free-tier activity and subsidised usage can create impressive numbers without demonstrating genuine product-market fit.
Paid inference demand is the metric that matters; it’s more sustainable, enabling longer term viability
ii) Revenue per GPU
A decentralised compute network is only sustainable if GPUs earn more value inside the network than they could elsewhere. If emissions are the primary reason providers participate, supply may disappear once incentives decline. GPU providers will run the numbers for opportunity cost:


iii) Router integrations: Distribution
Distribution is often more important than infrastructure itself.
OpenRouter integrations, coding agents, wallets, payment endpoints, developer tools and consumer applications are all potential sources of demand:


A payment endpoint is a route through which software can pay for a service directly, usually through an API.
iv) Verification
GPU spoofing, fake capacity and unreliable providers remain genuine risks.
Networks need robust hardware verification, encrypted traffic, reputation systems and meaningful penalties for poor behaviour.
v) Privacy guarantees
Private inference remains one of the strongest crypto AI opportunities, but the guarantees must be genuine. Marketing privacy is easy; secure execution, local-first architectures, data minimisation and auditable infrastructure are much harder to deliver.
vi) Token value capture
The strongest token models will connect demand directly to real inference usage. That could involve buybacks, burns, staking requirements, compute rights or revenue-linked mechanisms.

Broad AI narratives alone are unlikely to be sufficient over the long term.
9. Final Take
The inference market is where AI begins to resemble a financial system. Every generated token carries a cost, every endpoint operates with a margin, every agent loop creates recurring demand, every router functions as a market maker and every GPU network becomes a source of supply…
Traditional providers currently dominate the developer experience and enterprise trust layers. Crypto AI networks, however, are exploring a different frontier built around permissionless supply, private inference, verifiable compute, tokenised access and agent-native (unrestricted “KYC-less”) payments
In the near term, the winner is unlikely to be the most decentralised network. It is more likely to be the network that makes decentralised inference feel ordinary and dependable through fast endpoints, strong documentation, reliable uptime, transparent pricing, verified supply and genuine paid demand.
There are however greater risks with crypto protocols as attacks become more common and sophisticated with AI capabilities:

Chutes remains one of the most important projects to watch because it is among the closest to turning Bittensor-backed compute into a functioning inference market rather than simply another GPU narrative. Similarly with Eigen Labs “Darkbloom”
Akash and io.net represent the supply-side challengers, Targon represents the confidentiality thesis, Venice represents the private AI demand layer and NuNet represents orchestration for a more distributed compute future.
The broader thesis is straightforward”:
“AI models may become increasingly commoditised, but inference markets are unlikely to follow the same path.”
The greatest value will accrue to the entities that route the work, verify the work, settle the work and capture the demand.
That is where the next crypto AI opportunity is likely to emerge.
That’s a wrap for issue 181 of Sammy’s Snippets. I hope you enjoyed it.
Please leave me any questions or thoughts here - I will respond to everyone!
If you found this interesting, please consider subscribing to this Substack and following me on X for more related insights.
If you are interested in more formal reporting on Crypto AI and Robotics then Khala is my research product.
Disclaimer: The content of this newsletter is for informational purposes only. Nothing in this newsletter constitutes financial advice or a recommendation to buy or sell any asset. Always do your own research before making any investment decisions.
I hold positions in many of the assets discussed in this newsletter. For a full list of disclosures, please refer to the Khala Research website.
Follow me on X | Khala Research